

Agentic AI just had a big weekend, and I spent my Saturday and Sunday deep-diving it. If you’ve been waiting for a clean entry point, this is it.
Quick answer: Start a tiny lab around one high-friction workflow, pick a stack with tool calling and retries, add deterministic guardrails, and log everything. The catalysts landed on March 21 and March 22, 2026, from enterprise experiments to open models and dev automation. If you move now with loops and handoffs, you’ll ship usable agents before April.
I start a tiny lab around one high-friction workflow, pick a stack with tool calling and retries, add deterministic guardrails, and log everything.
What changed this weekend
Enterprise got hands-on with a finance AI lab
On March 22, 2026, Fortune highlighted Adobe’s CFO turning finance into an AI lab. Not a committee. A lab. Finance has real guardrails, touches every part of the business, and measures outcomes. If AI survives there, it can survive anywhere.
What I’m copying: pick one back-office workflow with friction and instrument it. Monthly close checklists, vendor reconciliation, or forecast commentary all work. Define success upfront with cycle time, error rate, and human touchpoints. If I cut two of those by 30 percent in 30 days, I have a case study.

NVIDIA pushed agentic workflows forward
On March 21, 2026, Security Boulevard reported NVIDIA’s expanded open model lineup across agentic AI, robotics, and drug discovery. Heading into March 22, Jensen Huang also backed agentic AI with Vera Rubin. Translation for me: the future is multi-step, tool-using agents that can call APIs, hand off tasks, and report outcomes. With more open models, I can prototype locally or cheaply in the cloud without burning budget.
Stack test I’m using: tool calling, a memory or scratchpad for multi-step tasks, and an event loop so the agent can try, fail, and try again. If a framework makes me bolt these on by hand, I skip it.
Stack test I’m using: tool calling, a memory or scratchpad for multi-step tasks, and an event loop so the agent can try, fail, and try again. If a framework makes me bolt these on by hand, I skip it.
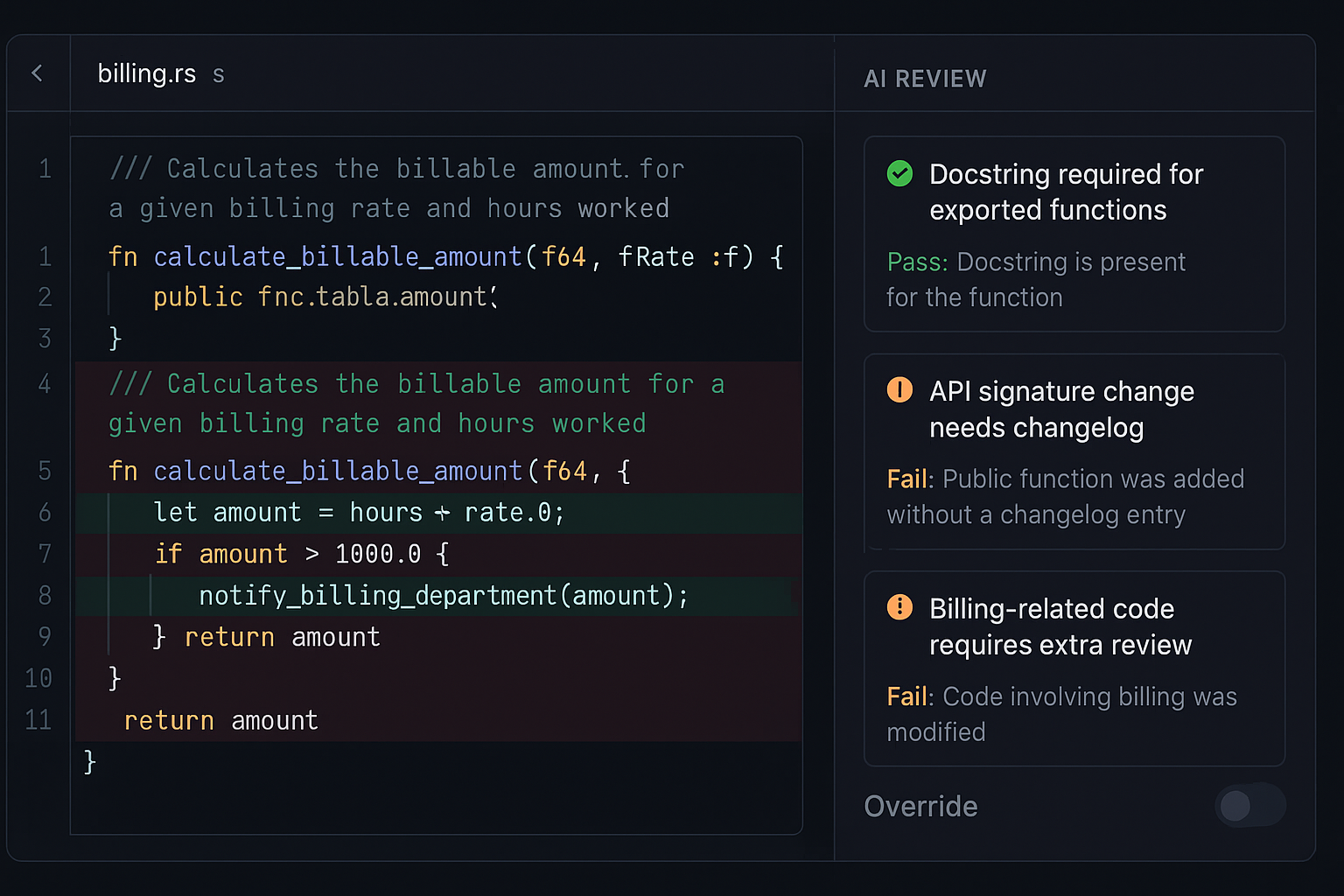
Linux is testing AI code review for Rust
On March 22, 2026, Phoronix noted Sashiko providing AI reviews on Rust code for the Linux kernel. That’s a high-scrutiny project putting AI in the review loop. For me, this signals a move from autocomplete to procedural gatekeeper. I can copy this without touching the kernel: define rules, let an agent flag violations, and keep humans as final approvers.
On March 22, 2026, Phoronix noted Sashiko providing AI reviews on Rust code for the Linux kernel. That’s a high-scrutiny project putting AI in the review loop. For me, this signals a move from autocomplete to procedural gatekeeper. I can copy this without touching the kernel: define rules, let an agent flag violations, and keep humans as final approvers.
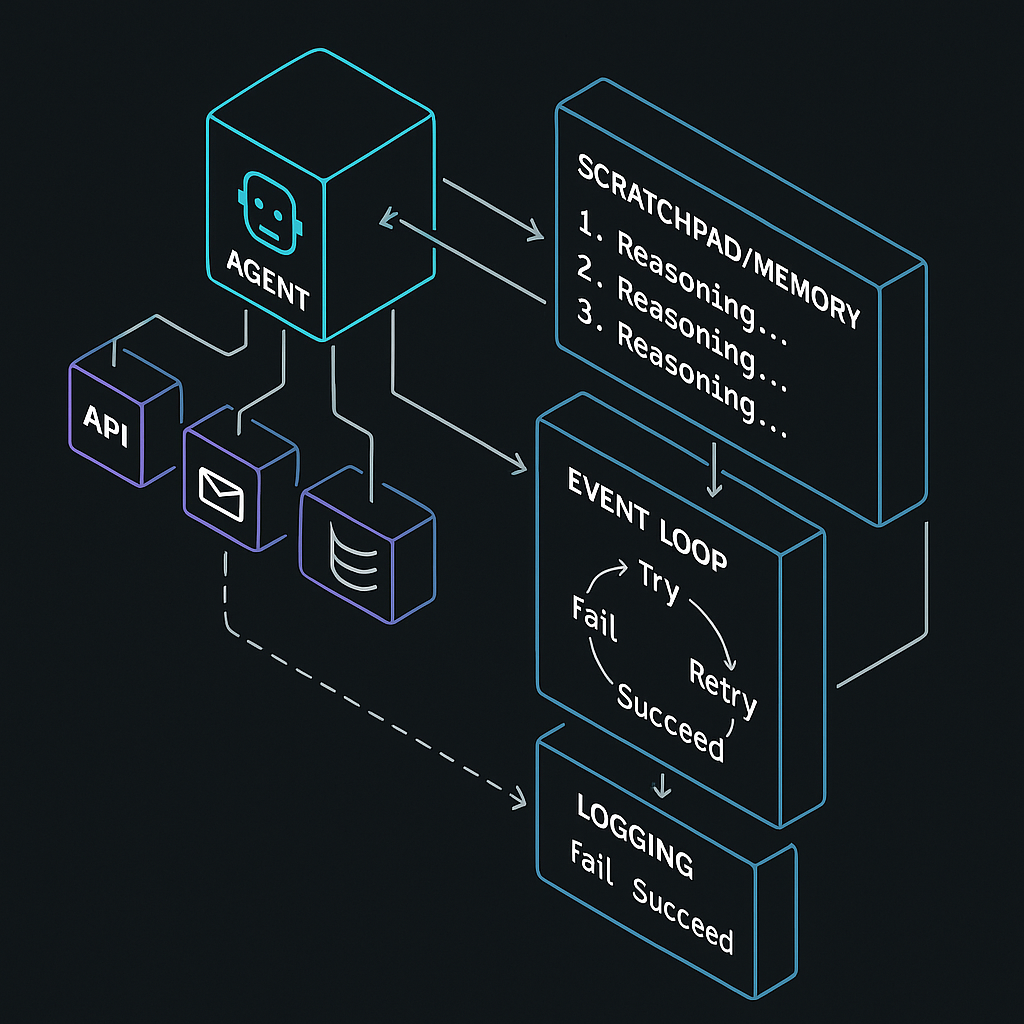
New rails are forming for agent coordination
On March 21, 2026, coverage of 0G framed it as a blockchain built for AI agents and a potential path to a trillion-dollar agentic AI economy. I’m not going on-chain today, but I’m designing for signed actions and verifiable logs so I can plug into maturing rails later without a rewrite.
I’m designing for signed actions and verifiable logs so I can plug into maturing rails later without a rewrite.
What this means if you’re starting now
The stack lit up from strategy to silicon. Enterprise teams are treating AI as experiments, the biggest chipmaker is favoring agents that act, open source is testing AI in high-stakes workflows, and infra is forming under the surface. I’m shifting from single-shot prompts to loops and handoffs. Instruments and logs first, UI later. If an agent cannot say what it did, why it did it, and what changed, I don’t ship it.
The starter kit I wish I had a year ago
I keep this lean so I can feel progress in a week and not blow the budget. Here’s what I’m actually doing:
- Pick one painful workflow with clear metrics. Example: pull monthly invoices, classify, and draft variance notes for finance to review.
- Choose a framework with tool calling, retries, and logging. Version prompts like code so changes are traceable.
- Add one deterministic guardrail. Static checks before deploy hooks, or regex sanity checks on numbers in finance text.
- Build a feedback button that queues failures. Fix nightly. These examples become training data later.
I cap the first target at under two hours of human supervision per week. If the agent saves 45 minutes, I keep going. If it needs a weekly babysitting meeting, the scope is wrong.
I cap the first target at under two hours of human supervision per week. If the agent saves 45 minutes, I keep going.
If you’re dev-focused, steal the Linux playbook
I’m setting three non-negotiables tied to my repo. Every exported function needs a docstring, public API signatures cannot change without a changelog entry, and anything touching billing gets an extra review. I’ll run an agent only on PRs that hit those rules and leave structured pass or fail comments. After two weeks, I’ll turn on soft blocks that require a human override. If it’s noisy, I tighten rules. If quiet, I add one more rule.
What I’m building next
I’m spinning up a tiny finance lab for a friend’s business inspired by the Adobe story. One agent fetches bank transactions, one classifies and reconciles invoices, and one drafts a monthly summary with variance notes. Humans sign off. Goal: 40 percent less manual reconciliation by month two.
In parallel, I’m prototyping a dev agent that checks API-breaking changes and enforces a stricter docstring template. If it cuts review time by 15 percent without spiking blood pressure for the senior dev, I’m shipping it.
On infra, I’m standardizing signed action logs now. Payload, signature, timestamp. If rails like 0G mature, I can plug in later without refactoring the world.
Cost, risk, and governance
I start with bounded tasks so tokens and compute stay predictable. Prompts live in version control like unit tests. I keep a basic budget sheet and update it on Fridays. If you’re regulated, loop in risk on day one. They hate surprises but love metrics and logs. Give them both.
When someone asks if the agent can go rogue, my answer is simple: it can’t. No tool, no action. Every tool is permissioned and logged. That model keeps people calm and architectures clean.
My rule is simple: no tool, no action; every tool is permissioned and logged.
FAQ
What is Agentic AI in practical terms?
Agentic AI is about multi-step, tool-using systems that can act, not just chat. Think agents that call APIs, pass tasks to each other, and report outcomes with logs you can audit. It’s closer to a workflow engine with reasoning than a single chatbot.
How do I pick my first workflow?
Choose something repetitive with clear success metrics and few edge cases. Finance reconciliation, support triage, or docstring enforcement are great. If you cannot measure cycle time, error rate, or human touchpoints, it’s not a good first target.
What stack features matter most?
I look for tool calling, a scratchpad or memory for multi-step reasoning, and an event loop for retries. Logging is non-negotiable. If these aren’t built in, you’ll spend your weekends gluing things together instead of shipping.
How do I keep costs under control?
Start with narrow scopes, cap tokens per run, and monitor usage daily. Cache intermediate results where possible and prefer open models for prototyping. Simple dashboards beat surprises at the end of the month.
When should I consider on-chain rails?
Not on day one. Design for signed, verifiable logs now so you can plug into identity, payments, or audit trails later. If agent-native rails mature, you’ll be ready without a migration fire drill.
Bottom line
Between March 21 and March 22, 2026, Agentic AI leveled up across enterprise practice, open models, developer workflows, and coordination rails. If you start now with a tiny lab, clear metrics, and one or two focused automations, you’ll be ahead while others are still pitching smarter chatbots. I’ll share results from my finance lab and code review agent soon. If you run a similar test, send me your metrics. Wins and misses both help.



